目的
工作中遇到一个需求,通过需要通过网站查询船舶名称得到MMSI码,网站来自船讯网。

分析请求
根据以往爬虫的经验,打开F12,通过输入船舶名称,观察发送的请求,发现返回数据的网址

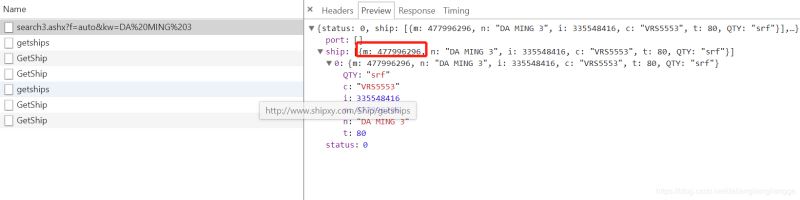
本身网址是一个get请求,直接用这个网址请求,也能返回数据,即网址本身并没有加密,这就简单许多,直接通过改变参数,就能实现数据的获取,马上开始动手

编写代码
代码中,通过request发送请求,为了不给服务器造成太大压力,每隔0.5秒发送一个请求,因为会出现查询不到的情况,通过exception判断,数据结果一是通过pandas中的to_excel存为excel文件,或者是直接通过pymysql入数据库,为了提高入库的速度,采用一次拼接三百条的方式入库
import requests
import os
import time
import pymysql
import pandas as pd
import re
'''
author:shikailiang
function:通过读取船舶数据,分别请求拿到json数据入库
'''
#定义入库的类
class company_ship_in_database:
def __init__(self):
self.conn = pymysql.connect(host="192.168.1.222", user="root", password="Cjh#Sjzx@", database="test", charset="utf8")
self.cursor = self.conn.cursor()
#获取当前文件的父级地址
self.last_path = os.path.abspath(os.path.dirname(os.getcwd()))
#写入mysql
def in_database(self,data_list):
#j用来对数据进行计数
j=1
#定义sql
sql = ""
#定义sql头
sql0 = "insert into bms_company_ship_test(oc_name,ship_name,mmsi) values"
rowcount=len(data_list)
for i in data_list:
#定义拼接sql
sql2 = (("(" + "'{}'," * 3)[:-1] + ")").format(i[1][0],i[1][1],i[0])
sql = sql + "," + sql2
# print(sql0 + sql[1:])
if divmod(j, 300)[1] == 0 or j == rowcount:
#如果执行错误回滚当前事务
# print(sql0 + sql[1:])
try:
self.cursor.execute(sql0 + sql[1:])
except:
#执行错误,回滚事务
self.conn.rollback()
continue
sql= ""
self.conn.commit()
j=j+1
#通过pandas写入excel
def in_xls(self, data_list):
df=pd.DataFrame(data_list)
#通过pandas实现存为excel
df.to_excel(self.last_path + r"\data\result.xls",header=False,index=False)
#请求船的方法
def company_ship_in_database(self):
data_path = self.last_path + r"\data"
file=open(data_path + "\company.txt")
data=[]
j = 0
for i in file.readlines():
#将船公司和船舶名称分开
chuan=i.strip().split()
dic={
'f':'auto',
'kw':chuan[1]
}
rq=requests.get("http://searchv3.shipxy.com/shipdata/search3.ashx",params=dic)
#判断是否请求成功
if rq.status_code==200:
try:
result_json=rq.json()
result=result_json['ship'][0]
#判断船舶数字部分是否相同
if re.search('\d+',result['n']).group()==re.search('\d+',chuan[1]).group():
result=result['m']
data.append([result,chuan])
else:
data.append(["", chuan])
except:
data.append(["",chuan])
else:
print(chuan + "请求错误")
time.sleep(0.5)
j = j + 1
if divmod(j,100)[1] == 0:
print("已经请求" + str(j) + "条")
# if j > 10:
# self.in_xls(data)
# break
self.in_database(data)
if __name__=="__main__":
company_ship=company_ship_in_database()
company_ship.company_ship_in_database()
尾记
写程序的过程中其实有发现一个问题,即我们请求的其实是输入文字时候自动发送的请求,其实有一个问题,如果我们需要查询的是"华为5"的船,但是如果系统中没有这个船,就是返回"华为548"扽船,所以在代码中需要做一个判断

即用正则提取出船的数字,然后和返回的船的数字进行比对,如果一致,即为同一条船舶

总结
以上所述是小编给大家介绍的基于Python实现船舶的MMSI的获取,希望对大家有所帮助,如果大家有任何疑问请给我留言,小编会及时回复大家的。在此也非常感谢大家对网站的支持!
如果你觉得本文对你有帮助,欢迎转载,烦请注明出处,谢谢!
免责声明:本站文章均来自网站采集或用户投稿,网站不提供任何软件下载或自行开发的软件!
如有用户或公司发现本站内容信息存在侵权行为,请邮件告知! 858582#qq.com
白云城资源网 Copyright www.dyhadc.com
暂无“基于Python实现船舶的MMSI的获取(推荐)”评论...
更新日志
2026年06月17日
2026年06月17日
- 小骆驼-《草原狼2(蓝光CD)》[原抓WAV+CUE]
- 群星《欢迎来到我身边 电影原声专辑》[320K/MP3][105.02MB]
- 群星《欢迎来到我身边 电影原声专辑》[FLAC/分轨][480.9MB]
- 雷婷《梦里蓝天HQⅡ》 2023头版限量编号低速原抓[WAV+CUE][463M]
- 群星《2024好听新歌42》AI调整音效【WAV分轨】
- 王思雨-《思念陪着鸿雁飞》WAV
- 王思雨《喜马拉雅HQ》头版限量编号[WAV+CUE]
- 李健《无时无刻》[WAV+CUE][590M]
- 陈奕迅《酝酿》[WAV分轨][502M]
- 卓依婷《化蝶》2CD[WAV+CUE][1.1G]
- 群星《吉他王(黑胶CD)》[WAV+CUE]
- 齐秦《穿乐(穿越)》[WAV+CUE]
- 发烧珍品《数位CD音响测试-动向效果(九)》【WAV+CUE】
- 邝美云《邝美云精装歌集》[DSF][1.6G]
- 吕方《爱一回伤一回》[WAV+CUE][454M]